對客戶分類,並針對不同的客戶屬性進行差異化行銷軟體,是掛在嘴裡的老生常談。但說的容易,要如何適當地對客戶分類,正確預測客戶未來趨勢走向,並不是件有標準答案的容易之事。近來找到一份Python教學的網路資料(Data Driven Growth,作者Barış Karaman,連結網址https://towardsdatascience.com/data-driven-growth-with-python-part-1-know-your-metrics-812781e66a5b),其中有提到如何利用Python數據分析技巧,處理客戶分類問題,除了程式編碼外,也從中學到一些之前未曾想過的東西。
客戶分類資料分析,可分為4個步驟:
1. 選擇以何種指標作為客戶分類之依據,按機器學習術語,將其稱為標籤(label)。
2.決定影響客戶分類結果(標籤)的因素有那些,在機器學習領域,這些因素被稱為特徵(feature)。
3.選擇適當的機器學習模型,從客戶往來資料,預測客戶未來趨勢,並驗證模型有效性。
4.改善及增進模型預測效能。
在設計客戶分類模型時,已假設「特徵」與「標籤」二者間具有因果關係,為突顯前因(特徵)後果(標籤)的效應,當被觀察的資料為時間序列形式時,通常會將資料切分為二段期間,前段區間只看「特徵」類數據,「標籤」數據則在後段區間,以此觀察前段「特徵」如何影響後段「標籤」。seo
Barış Karama就一份50多萬筆訂單明細表資料(資料檔案下載連結網址:https://www.kaggle.com/vijayuv/onlineretail)進行客戶分類分析,他將資料按時間區分為二批,一批為2011/3~2011/5三個月資料,另一批為2011/6~2011/11的六個月資料,而相關步驟:
1.客戶分類指標(標籤)
客戶分類指標並非一成不變的,需視目的的不同,而採用不同的指標,像在評估客戶整體貢獻度時,在一定期間內,如半年內,其總購買金額,可能會是個適當的指標;但用在評估行銷軟體活動成效時,僅追蹤行銷軟體活動期間的購買金額,會是個更有效的指標;而像3C產品的購買金額,用在觀察3C產品行銷軟體活動時,是更適當的指標。
作者Barış Karama在案例中,以客戶的生命週期價值(Lifetime Value,LTV,總購買金額 - 總成本)作為客戶分類指標。作者在文中特別強調,如何選擇生命週期,需視產業特性而定,像設定為一年,對某些產業而言太長了,但對另一些產業來說,可能又太短了。作者將客戶生命週期定為半年作為範例,以每位客戶於2011/6~2011/11六個月內生命週期價值訂為分類指標。
2.影響客戶行為的因素(特徵)
是否存在因果關係,是決定特徵元素時的重要標準。例如客戶的性別或居住地,列為特徵項目,一般而言並無不妥;但若說客戶的email伺服器網域名稱,會影響到他個人購買行為,似乎就太牽強了。
作者Barış Karama以客戶LTV觀察期(2011/6~2011/11)之前三個月(2011/3~2011/5)的RFM指標,設為影響特徵因素。RFM各代表三項指標,我們可用K-平均集群法(k-means clustering)技巧,向每位客戶分項分群計分,最低0分,最高3分:
•Regency:最近消費日期,越近分數越高。
•Frequency:消費頻率,次數越多,分數越高。
•Monetary:總購買金額,金額越高,分數越高。
三項總分,最低0分,最高9分。
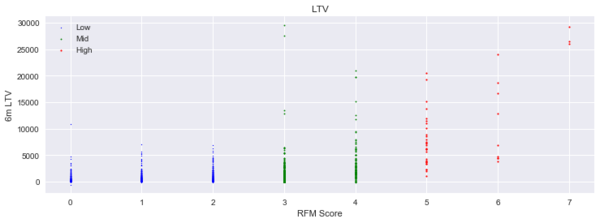
得出前三個月各個客戶的RFM分數後,接著檢視該分數與之後六個月的客戶LTV值二者間的關聯性,附圖為視覺化的呈現。橫軸為RFM分數,縱軸為LTV值,圖形中每個點,代表每個客戶各自的RFM及LTV值。藍色點的RFM為0~2分,綠色為3~4分,紅色則為5分以上。從圖形可明顯看出,前三個月RFM分數較低者,接下來六個月的LTV值也相對較低;而RFM分數較高者,雖有較高比例者能有較高的LTV值,但低LTV值者也不少,看來消費金額比較低的客戶,其RFM-LTV的關聯性才會比較明顯。
3.選擇適當的機器學習模型
因我們的目的,是希望對機器學習模型餵入資料學習後,即能藉由客戶前三個月的RFM指標,來預測之後六個月的客戶LTV分類結果,因此我們先再用K-平均集群法,依客戶的LTV值將他們分為三群,然後再看看單靠前三個月的RFM資料,是否能正確預測事後客戶的LTV分類。
此例的機器學習模型,我們選用XGBoost套件的classifier學習模型,學習成效結果為:
•LTV值最低的類群,其被模型正確預測分類的成功機率可達八成以上。
•LTV值中高分類群,其被模型正確預測分類的成功機率,則只有五成左右,差強人意。
4.改善及增進模型預測效能
有些技巧可在「數據」上改進模型的效能,但有項原則需謹記在心,「數據分析」是手段而非目的,重點在「分析目的」,而非「數據本身」,切記不要為了追求完美的數據,而違背了最初要分析的目的。下面為增進模型效能的相關技巧:
• 增加觀察資料樣本數
增加樣本數,通常即能增進模型效能。原先計算客戶RFM值時,我們只觀察三個月的資料,若觀察期延長為六個月,隨著樣本數增加,或能增加模型效能。但有一點需注意,因分析的資料集,僅有九個月的完整資料期間,假如為將RFM計算期延長為六個月,而把客戶的LTV值縮短為三個月,會是個大錯特錯的作法,因客戶生命週期,在本例的產業特性為六個月,而非三個月,架構模型來預測三個月的客戶LTV值,即已背離商業上的分析目的。
•增加模型的特徵變數
例如原資料集裏另有客戶所居住國家的資訊,或可放進模型裏與RFM一起分析。
•調適機器學習模型的超參數設定
機器學習模型在資料學習運算前,通常有些先決條件需事先設定,這些設定的條件,稱為超參數。就本例而言,我們對XGBoost機器學習模型,事先設定其決策樹的節點深度為5層(max_depth=5),我們可嘗試改變這項設定,看看最後結果是否有改善。
•換另一個機器學習模型
當然換模型也是一個可行選項,如將XGBoost模型換為Gaussian Naive Classification模型,看看結果有何不同。

 留言列表
留言列表

